Laporan Praktikum Distribusi Frekuensi
LAPORAN PRAKTIKUM
STATISTIK DISTRIBUSI FREKUENSI
1.1. Latar Belakang
Statistik merupakan salah satu cabang dari ilmu matematika yang di dalamnya mempelajari suatu pengukuran, observasi dan analisis. Statistik mempunyai arti dasar yaitu suatu data ringkasan yang berbentuk angka. Sebagai contoh kecil adalah mengenai data tentang penduduk, data tentang guru-guru atau data tentang mahasiswa di perguruan tinggi. Dalam arti yang lebih dalam, statistik adalah suatu ilmu yang mempelajari mengenai bagaimana cara mengumpulkan data, mengolah data, menyajikan data dan menganalisi data dengan mempertimbangkan unsur ketidakpastian berdasarkan konsep probabilitas.
Statistik sendiri berasal dari kata “status” dalam bahasa latin, yang sama artinya dengan kata “state” (bahasa inggris) yang berarti adalah negara. Awal mula suatu kata statistik, diartikan mengenai suatu kumpulan keterangan yang berupa angka ataupun non angka tetapi memiliki arti yang penting dan berguna untuk negara. Setelah berkembangnya suatu ilmu, maka statistik dijadikan sebagai kumpulkan keterangan yang hanya berupa angka dan memberikan gambaran mengenai keadaan, peristiwa atau gejala tertentu.
SPSS (Statistical Package for the Social Science) merupakan software statistik yang pada awalnya digunakan untuk riset dibidang sosial dan melayani berbagai jenis user. SPSS merupakan paket program statistik yang paling populer dan paling banyak digunakan di seluruh dunia. Hal inilah yang yang membuat kepanjangan SPSS saat ini adalah Statistical Product and Service Solution. Dengan SPSS semua kebutuhan pengolahan data dapat diselesaikan dengan mudah dan cepat. Kemampuan yang dapat diperoleh dari SPSS meliputi pemrosesan segala bentuk file data, modifikasi data, membuat tabulasi berbentuk distribusi frekuensi, analisis statistik deskriptif, analisis statistik lanjut yang sederhana maupun kompleks, pembuatan grafik dan sebagainya.
1.2. Tujuan
Pada laporan ini akan dijelaskan bagaimana cara menggunakan aplikasi SPSS dan cara mengeluarkan output tabulasi distribusi frekuensi.
BAB II
TINJAUAN PUSTAKA
Langkah-langkah pengolahan data pada SPSS sangat praktis karena hanya menginput data tanapa menghitung dengan rumus-rumus statistika. Setelah data diinput pada SPSS editor kemudian kita mencari alat analisis yang diperlukan, memasukka variabel dan lain-lain, kemudian klik Ok, setelah itu proses olah data dilakukan dengan sangat cepat, singkat, akurat, cermat, handal dan keluarlah output data SPSS (Bisono,2013).
Berbagai metode statistik memungkinkan kita dapat melihat, mencari dan menyimpulkan hal-hal yang jauh diluar data yang dikumpulkan dan dapat masuk kebagian pengambila keputusan melalui generalisasi dan peramalan. Perkembangan teknologi informasi melahirkan perangkat lunak paket-paket metode statistik yang sangat membantu da mempermudah mnghitung, meramal serta menganalisis masalah yang akan dipecahkan (Rahmini,2001).
Tabel distribusi frekuensi adalah alat penyajian data statistika yang berbentuk kolom dan baris yang didalamya terdapat susunan data yang telah dikelompokkan menurut kategori tertentu. Tabel distribusi frekuensi memiliki macam-macam jenis. Yaitu tabel distribusi frekuensi data tunggal, tabel distribusi frekuensi data kelompok, tabel distribusi frekuensi relatif, tabel distribusi frekuensi kumulatif dan tabel distribusi frekuensi relatif-kumulatif. Terdapat istilah-istilah yang digunakan dalam tabel distribusi frekuensi. Istilah tersebut yaitu kelas interval, batas atas, batas bawah, tepi bawah/tepi atas, nilai tengah data, panjang kelas interval (Riani,2023).
BAB III
PEMBAHASAN
A. Distribusi Frekuensi
Untuk melakukan pengolahan data di SPSS, tahap pertama yang harus dipersiapkan adalah memiliki datanya terlebih dahulu di exel ataupun media lain seperti google sheet agar memudahkan membedakan data mentah dan data yang akan di input pada aplikasi SPSS.
Data Mentah


Tabel kedua dan ketiga masing-masingnya memberikan distribusi frekuensi untuk jenis kelamin responden dan pendidikan responden. Tabel distribusi frekuensi menampilkan lima kolom sebagai berikut:
· ☑Kolom pertama: kategori yang difrekuensikan (sebagai contoh pada jenis kelamin adalah pria dan wanita).
☑Kolom kedua: frekuensi masing-masing kategori.
☑Kolom ketiga: persentase frekuensi masing-masing kategori (persentase dihitung dari total observasi termasuk observasi missing).
☑Kolom keempat : persentase frekuensi masing-masing kategori tetapi persentase dihitung dengan mengeluarkan observasi missing. (Catatan: berhubung tidak ada observasi missing, baik untuk jenis kelamin maupun pendidikan, maka kolom 3 dan 4 menjadi sama).
☑Kolom kelima: Cumulative Percent yaitu persentase kumulatif yang dihitung dari valid percent. Sebagai contoh pada tabel frekuensi pendidikan. Baris pertama adalah 22,2 persen. Pada baris kedua adalah 55,6 persen yang dihitung dari 22,2 + 33,3 (catatan: perbedaan perhitungan karena pembulatan).
B. Pengelompokan Data
Untuk dapat menampilkan ukuran statistik distribusi frekuensi dari kumpulan data. diperlukan terlebih dahulu mengelompokkan data dalam kategori (pendidikan SD, SLTP,SLTA, DIII, dan S1) atau data sudah dikategorikan dalam kelompok-kelompok interval tertentu misalnya pendapatan rendah (< 1.000.000), menengah (1.000.000 – 2.000.000), tinggi (>2.000.000), maka kita dapat secara langsung membuat distribusi frekuensinya. Tetapi jika data belum terkelompok dalam kategori-kategori tertentu, tabel distribusi frekuensinya akan sangat panjang mengikuti keragaman dari nilai-nilai data tersebut. Misalnya jika dibentuk tabel distribusi frekuensi dari data umur, maka akan terbentuk tabel distribusi yang tidak ringkas, sehingga kita akan sulit menarik kesimpulan dari data tersebut, seperti terlihat dibawah ini:


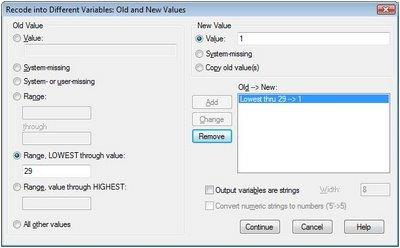
Misalnya variable umur akan dikelompokkan menjadi ≤ 29, 30 – 39, 40 – 49, dan ≥ 50. Untuk mengelompokkan umur ≤ 29, pada bagian Old Value, klik Range, LOWEST through value, kemudian isikan pada kotak dibawahnya angka 29. Pada bagian New Value, pada kotak Value isikan angka 1, lalu klik Add (lihat tampilan diatas). Untuk mengelompokkan umur 30 – 39, pada bagian Old Value, klik Range, kemudian isikan pada kotak dibawahnya angka 30 dan kotak dibawah through angka 39. Selanjutnya pada bagian New Value, pada kotak Value isikan angka 2, kemudian klik Add

Dengan cara yang sama lakukan untuk kelompok umur 40 – 49 dan pada New Value beri kode 3. Selanjutnya untuk kelompok umur ≥ 50, pada bagian Old Value, klik Range, value through HIGHEST, isikan pada kotak dibawahnya angka 50. Selanjutnya pada bagian New Value, pada kotak Value isikan angka 4, lalu klik Add. Setelah selesai memberikan kode untuk pengelompokan umur ini, kemudian klik Continue dan OK.
Berikan keterangan untuk masing-masing kode pengelompokan umur tersebut pada Value Label dengan kode 1 (≤ 29), kode 2 (30-39), kode 3 (40 – 49), kode 4 (≥ 50). Lalu bentuklah distribusi frekuensi untuk kelompok umur tersebut sehingga output adalah sebagai berikut:

BAB IV
Kesimpulan nya adalalah aplikasi SPSS (Statistical Program for Social Science) merupakan aplikasi pengolah data untuk mendapatkan output statistik. Aplikasi ini memudahkan pengguna yang memerlukan data secara statistik meliputi tabulasi distribusi frekuensi.
Vidio Youtube
DAFTAR PUSTAKA


Komentar
Posting Komentar